Compiling Scala Native in a GitHub Action; Alternatives to GraalVM


Scala Native is a compiler and JDK written in Scala with the goal of removing Scala’s dependency on the JVM. This isn’t meant to achieve a higher performance such as with JDKs, and it is targeting a specialized use-case not considered to be today’s typical Scala development. Its competitors are Rust and Go, not GraalVM, Java or Kotlin. This article goes through common steps and challenges encountered when compiling Scala Native for linux with a GitHub Action.
After 7 years Scala Native is at pre-production maturity version 0.4.17.
Different versions of OpenJDK
To avoid confusion between Scala Native, and Scala compiled natively it’s important to be clear on the goals of alternative OpenJDK implementations. Initially Oracle released Java and Java’s JDK/JRE but licencing has changed causing open source, free to use, alternatives to emerge that are compatible with the Java SE Specification.
From a high level, whichjdk.com highlights the JDK products supported by various cloud computing entities; AWS, Azure, IBM, SAP, and RedHat all have JDKs. There are minor differences such as in their Garbage Collector tuning, but for the most part they are unremarkable in their similarity.
Eclipse OpenJ9
Eclipse OpenJ9 is a cloud optimized JDK which rethinks OpenJDK implementation while offering full compatibility. With focus on JVM startup times and memory management, the notable new features include:
- Checkpoint/Restore in Userspace (CRUI),
- Class Data Sharing,
- partial Ahead-of-Time (AOT) compilation, and
- aggressive GC tuning.
GraalVM
The goal of GraalVM is of Java using strictly Ahead-of-Time (AOT) compilation, rather than using Java’s Just-in-Time Compilation. This is a breaking change but allows compilation to a native executable rather than Java’s class bytecode.
Scala has 2 SBT plugins with GraalVM support:
The benefits of GraalVM native executable is removal of the JVM initialization time and the removal of any unreachable code, resulting in smaller packages which boot quickly. Unfortunately the largest downside to the removal of JIT is removal of any runtime performance optimization based on use. The AOT is able to optimize but without any visibility into common paths and hotspots it is from a strictly static perspective. In addition, the optimizations come from Java bytecode which has already removed some key ingredients for full static analysis. In real-world benchmarks, GraalVM performance typically lags behind JIT competitors for long-running tasks.
Another breaking change in GraalVM use is the inability to use Java reflection and runtime code generation. This is more common in Java than in languages such as Scala, but any program can be affected. There are 2 approaches to work around this limitation:
Quarkus and optimized libraries written without JIT requirements
The popular Kubernetes focused framework Quarkus avoids JIT with specialized versions of standard libraries. The changes necessary can be minor, allowing for a well-supported ecosystem of popular libraries available as extensions to Quarkus, without notable lag to official library releases. However, support for any library not available as an extension will rely on the second JIT alternative.
Reflection Metadata Collection and Code Hints
The GraalVM compiler can perform static analysis of code to learn about certain types of JIT and reflection, but runtime observation with the GraalVM Tracing Agent is required. Code needs to be run under all execution paths, and the Tracing Agent will record all usages of the Java Native Interface (JNI), Java Reflection, Dynamic Proxy objects, or class path resources. These will then be supplied as a JSON document to the AOT on the next compilation. The obvious problem is triggering all executable code paths during the debugging cycle, making this (theoretically) a trial and error process.
Motivations for Scala Native
ScalaJS, the Scala to JavaScript Transcompiler
The focus of Scala Native isn’t explicitly native execution, it is in the removal of the restrictive JDK dependency. Scala Native has 2 supported outputs:
ScalaJS can realistically only transcompile to JavaScript if it can remove any unused overhead imposed by the JDK. Typical JavaScript use cases are web oriented, where code sizes dictate latency and observed performance.
The JDK and Java bytecode are opinionated in their interactions with other native code. The Java Native Interface (JNI) is an unnecessary and in often a performance restricting abstraction that is only necessary to bridge between the JRE and external native code. The LLVM linking for native-native interactions offers low level primitives such as pointers and unsafe memory access that can be necessary to achieve top performance. Scala Native includes additional Scala support for the low-level C/C++ primitives directly which cannot be represented in Java.
Executables and Jars
Java can be run directly in the JRE using java -jar. It is essentially just as easy to run a Jar as a native
executable (assuming a JRE is installed). As noted previously, AOT executables may initialize quicker but often bested
by JIT on long-running performance. This leaves short-lived container applications such as: AWS Lambda, serverless
functions, and Kubernetes the primary target for GraalVM, with standard JDK or OpenJ9 remaining the best choice for
server instance deployments or longer running serverless. So where exactly does Scala Native fit in?
CLI Tools and JNI-heavy applications
The benefit of a Scala Native LLVM executable is it is just another C/C++ program. In the same way Rust, Zig and Go have emerged as replacements to C/C++, Scala Native offers the same compatibility and performance with a familiar and powerful Scala language. It is the native compatibility and low-level features brought to Scala via Scala Native that make Scala Native a compelling choice with applications which require low-level management or direct hardware interactions.
Compiling Scala Native in a GitHub Action
As outlined previously, the use-case of Scala Native is typically a low-level CLI application. This remainder of this article deviates from this by working through a Scala application which will not benefit from Scala Native.
This is not a recommendation by the author to apply Scala Native to a similar project, merely a discover exercise
GitHub Action Runners
The linux server configurations outlining OS and installed software is available, and includes suitable CLang and LLVM versions. For local development the Scala Native install guide covers for macOS (using brew) and linux using apt.
Compiling additional C libraries with CMake
It is very likely that a Scala Native will have a library dependency not installed on the GitHub Runner. In our application the FS2 functional library requires the Amazon AWS TLS/SSL library S2N. Security and cryptography libraries are likely to be native dependencies both because they likely already exist as high-performance native implementations, and secondly because Scala Native JDK may omit them due to security concerns around implementation.
Compiling a C application with CMake is a straight-forward addition to the GitHub Action YML:
- name: Compile and Install AWS S2N-TLS
run: |
# clone s2n-tls
git clone --depth 1 https://github.com/aws/s2n-tls.git
cd s2n-tls
# build s2n-tls
cmake . -Bbuild \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=./s2n-tls-install
cmake --build build -j $(nproc)
CTEST_PARALLEL_LEVEL=$(nproc) ctest --test-dir build
cmake --install build
Linking C library paths in SBT
When linking to a GitHub Action compiled C libraries such as S2N, the library needs to be in a path scanned by LD.
Because LD is being called by CMake and not GCC, typical environmental variables such as LD_LIBRARY_PATH and
LIBRARY_PATH do not work.
TODO: CMAKE_EXE_LINKER_FLAGS LDFLAGS
The easiest option is to include the path in build.sbt though this path will differ between local development
and within the GitHub Action.
For example, within the build-action-file-receiver project on GitHub, the runner installed S2N in the following path:
nativeLinkingOptions += s"-L/home/runner/work/build-action-file-receiver/build-action-file-receiver/s2n-tls/s2n-tls-install/lib"
Scala Native library dependencies in SBT
The build-action-file-receiver is a typical Scala web server application, but with compatibility to run Scala Native making
it suitable for this article. Scala Native compatibility is dictated by the availability of Scala Native versions for
all library dependencies. These are exist as separate artifacts:
- https://repo1.maven.org/maven2/co/fs2/fs2-core_3/3.9.4/fs2-core_3-3.9.4.jar (1.5MB)
- https://repo1.maven.org/maven2/co/fs2/fs2-core_native0.4_3/3.9.4/fs2-core_native0.4_3-3.9.4.jar (3.7MB)
This is indicated in build.sbt by using the %%% operator instead of % / %%:
Typical Scala:
libraryDependencies ++= Seq(
"org.http4s" %% "http4s-ember-client" % http4sVersion,
"org.http4s" %% "http4s-ember-server" % http4sVersion,
"org.http4s" %% "http4s-dsl" % http4sVersion,
"org.typelevel" %% "log4cats-core" % "2.6.0",
"co.fs2" %% "fs2-io" % "3.9.4",
"org.scala-lang.modules" %% "scala-xml" % "2.2.0",
"org.scalatest" %% "scalatest" % "3.3.0-alpha.1" % Test,
"org.typelevel" %% "cats-effect-testing-scalatest" % "1.5.0" % Test,
)
Scala Native:
libraryDependencies ++= Seq(
"com.armanbilge" %%% "epollcat" % "0.1.4",
"org.http4s" %%% "http4s-ember-client" % http4sVersion,
"org.http4s" %%% "http4s-ember-server" % http4sVersion,
"org.http4s" %%% "http4s-dsl" % http4sVersion,
"org.typelevel" %%% "log4cats-core" % "2.6.0",
"co.fs2" %%% "fs2-io" % "3.9.4",
"org.scala-lang.modules" %%% "scala-xml" % "2.2.0",
"org.scalatest" %%% "scalatest" % "3.3.0-alpha.1" % Test
)
The %%% operator and SBT nativeLink task to compile the native executables/libraries are added by the
SBT Scala Native plugin, and additional
configuration options are straight forward parameters covered in the setup documentation.
Code Changes Required to Support Scala Native
Cross Compiling
There exists the SBT-CrossProject plugin that will hopefully alleviate issues with compiling to Scala 3 Jar and Scala 3 Native.
TODO: Examples on this working.
Partial JVM Implementations
Multithreading and Runtime Environment
The Scala Native runtime environment is a very basic implementation lacking a threading model and thread synchronization primitives. The current recommendation is to import and use necessary C libraries. To achieve basic functionality libraries such as FS2 require an additional library to operate in Scala Native, such as the I/O runtime epollcat.
Scala libraries are typically built around event-loops and/or monads, so the use of Node.js’s I/O event library libuv has been made available as Scala Native Loop.
Cryptography and java.security package
While the Scala Native lists many JDK packages as implemented,
some packages such as java.security have intentionally been left incomplete. This can have unexpected touch points,
so while a TLS/SSL implementation was a predictably omitted, the dummy implementation of all hash functions, including
MD5 and SHA1
in java.security.MessageDigest
was not.
object MessageDigest {
def isEqual(digestA: Array[Byte], digestB: Array[Byte]): Boolean =
true
def getInstance(algorithm: String): MessageDigest =
new DummyMessageDigest(algorithm)
}
private class DummyMessageDigest(algorithm: String)
extends MessageDigest(algorithm) {
override protected def engineDigest(): Array[Byte] = Array.empty
override protected def engineReset(): Unit = ()
override protected def engineUpdate(input: Byte): Unit = ()
override protected def engineUpdate(
input: Array[Byte],
offset: Int,
len: Int
): Unit = ()
}
Scala-XML
The incompleteness of the Scala-XML library was a little puzzling. What is the point of publishing an XML library when it can’t pass the most simple, obvious use-case.
[error] Found 21 missing definitions while linking
[error] Not found Top(javax.xml.parsers.SAXParser)
[error] at file:/home/runner/work/scala-xml/scala-xml/shared/src/main/scala/scala/xml/factory/XMLLoader.scala:51
The problem with "org.scala-lang.modules" %%% "scala-xml" % "2.2.0" is that javax library hasn’t been implemented.
Runtime Observations
Performance and Memory
For a cross-compiled project, the http-maven-reciever project compiled to an 27.9MB executable “Fat Jar”.
The debug-mode Scala Native produced a 41.4MB linux executable.
[info] done compiling
[info] Linking (2666 ms)
[info] Checking intermediate code (quick) (194 ms)
[info] Discovered 6982 classes and 47495 methods
[info] Optimizing (debug mode) (3964 ms)
[info] Generating intermediate code (5599 ms)
[info] Produced 10 files
[info] Compiling to native code (17076 ms)
[info] Total (29698 ms)
[success] Total time: 32 s, completed Feb. 7, 2024, 10:29:39 a.m.
35MB
[error] ld: Assertion failed: (aliasSectionNum == sectionNum && "alias and its target must be located in the same section"), function assignAliasAtomOffsetInSection, file Layout.cpp, line 3324.
[error] clang: error: linker command failed with exit code 1 (use -v to see invocation)
TODO: optimized release mode file size TODO: startup with Scala 3 Jar TODO: load benchmarks with Scala 3 Jar TODO: memory footprint with Scala 3 Jar
Unit Tests
Scala Native officially supports the major testing libraries. TODO: running tests
Debugging
The debugging of native executables and libraries is not as developer friendly as JIT code. There is less debugging information available within the executables for IDEs to interpret. A typical debugging experience using LLDB is dramatically different from JVM tooling; meaning cross compilation has practical utility within the entire software development lifecycle.
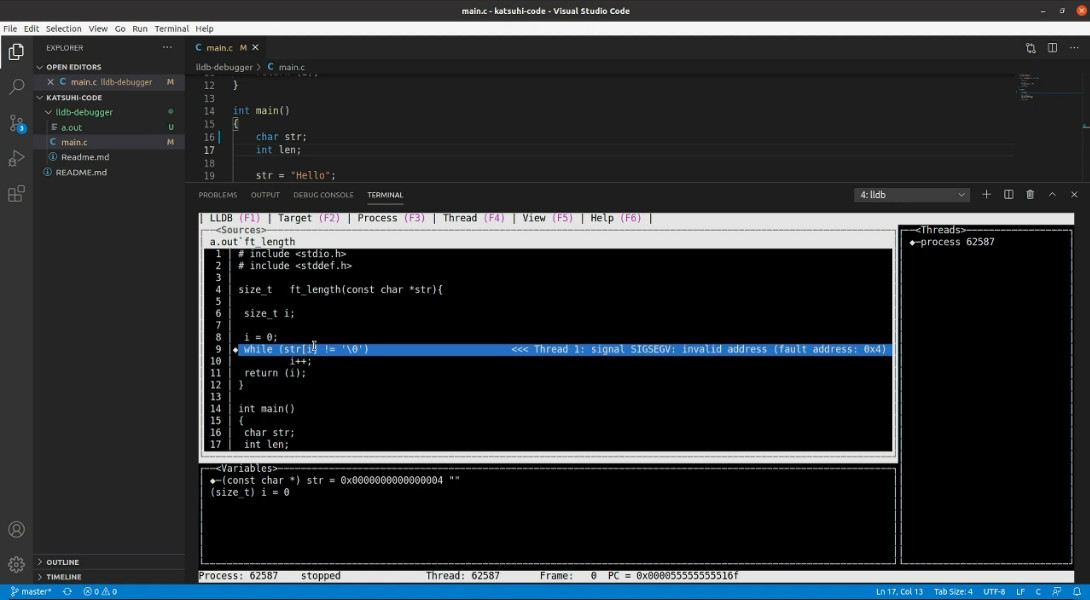
Conclusions
Pros
- Fast and direct calling of native dependencies
Cons
- Painful debugging
- Long compile/linking times
- Needs Scala Native to compatible dependencies
- Subtle code changes
- Hard to use resource and configuration files
- Usually need to make JVM version work
Scala Native is a welcome addition to the C/C++ alternatives for Scala developers. This ecosystem has room to grow as performance and latency bottlenecks are no longer determined by hardware, but by the minuscule overheads determined at compile time. Latency can’t be solved by more parallelism or faster CPUs, but by slimming the instruction and cache footprint of code. Rust and Go have taken off in popularity, and Scala Native, if done right has all the same benefits.
But to make this a compelling choice, Scala Native shouldn’t be confused with Scala’s JVM presence. Longtime users of
ScalaJS are familiar with the restrictions to the lihaoyi libraries, and Scala Native have the same burden. Projects
using Scala Native should be selective, and primarily oriented to using C native libraries or staying within the small
pockets of JVM libraries such as lihaoyi or typelevel which have been early native adopters.
The advice to use Scala Native for only CLI tools is on point. While it will be a long time before this changes, it doesn’t need to for Scala Native to be successful. The JDK dominated space doesn’t need native via Scala Native, advancements in alternative JDKs such as GraalVM are already offering native support in a more suitable and easier to apply route. As it’s always been, select the right tool for the right job.
Sources

Build Action File Receiver
HTTP server that receives artifact uploads and verifies MD5 against Maven.Data Transfers and Egress within a GitHub Action

The free tier of GitHub Packages has limited bandwidth to download private artifacts; which can make it unsuitable for use in a CI/CD pipeline for projects on a budget. In an effort to increase GitHub Packages’ usability, this article develops an alternative approach minimizing the dependency on GitHub Packages as hot storage, but preserving it as a viable cold storage, durable storage solution.
Http4s Streams and Multipart Form-Data File Uploads


Streaming is the primary mechanism to reduce memory requirements for processing large datasets. The approach is to view only a small window of data at a time, allowing data to stream through in manageable amounts matching the data window size to the amount of RAM available. A practical example is a file-upload, where multi-GBs file streams can be handled by MBs of server RAM. However, enforcing streaming in software code is prone to errors, and misuse or incompatible method implementations will lead to breaking stream semantics, and ultimately to OOM exceptions. This article focuses on streams within the context of file uploads, using the Http4s library for examples.

